What's in a Link: Decoding a URL
The fundamental and most powerful feature of the World Wide Web is the ability to 'click a link' and be 'transported' to the content you're looking for. In essence though, that understanding is backwards. In fact, when you 'click a link', what you're actually doing is sending a command out to some server on the internet, which then sends the requested data back to you. Your web browser then decodes the information, and, in many cases, automatically runs the program contained in it.
With the flick of a finger, your computer is running whatever program some server on the internet wants to send you. Sound dangerous? It is! But there is a way to be somewhat assured about what you're going to get from a link before you click.
First, you need to know how to see the actual URL (Uniform Resource Locator) behind a link before you click on it. Most email programs and web browsers have a means of displaying the URL or target of a link when you simply 'hover' over the link, or hold your mouse cursor over it before you click. Check in the lower left-hand corner of the window, as in the screenshot below:
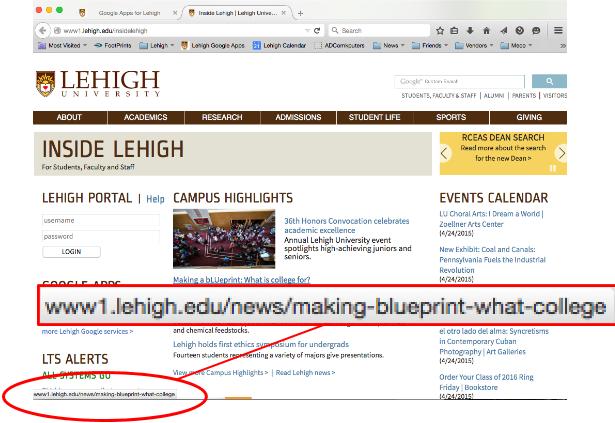
Second, you need to know what the parts of a URL are, and how they describe the kind of data you'll get when you click on the link. A URL always contains a few standard pieces as shown in the diagram below:

While you don't always see all of those parts in use, the primary element to look for is the 'root domain'. This is the part of the URL that someone paid for, and is therefore potentially traceable to a real person. Notice that the domain has two parts - a unique domain name, and a top level domain name that categorizes it generally (.com for commercial, .gov for government, .edu for educational institutions, .org for non-profits). While these top-level domains are intended to be indicative of the networks and nations to which they belonged, there are a growing number of exceptions, and their number and diversity are increasing steadily (.biz, .tv, .me, etc). Nevertheless, country codes are still in fairly wide use, and are often helpful to let you know the nationality of the server from which you're getting data (.ru=russia, .br=brazil, .de=Germany, .cn=China). Usually, you know if you should expect to be dealing internationally. Generally, if you're confident in the validity of the domain (it matches information published via other media), you can be fairly confident that the content of the pages was created by the organization that owns it.
Also useful is the filename or extension. Extensions such as .htm and .html indicate static pages, usually without scripts. Extensions like .php and .aspx indicate the output of scripts that run on the server. Not having a file specified tells the server to find the default file in the web server's directory. Additional '/' characters indicate sub-directories within the server's main directory.
For immediate help, contact the LTS Help Desk (Hours)
EWFM Library | Call: 610-758-4357 (8-HELP) | Text: 610-616-5910 | Chat | helpdesk@lehigh.edu
Submit a help request (login required)